集群方式有三种:Replica Set、Sharding、Master-Slaver三种方式
常用的主要是副本集和主从模式,主从模式比较好理解,即一个master和一个slave节点,master节点负责读写,slave在master宕机的时候可以提供读服务,当然也可以通过配置参数实现在访问量高的时候让slave节点也提供读服务;
而副本集模式比较特殊,但这种模式也是比较稳定,可靠,同时在一定的情况下能够实现自动容错的机制,它主要包括如下几部分,
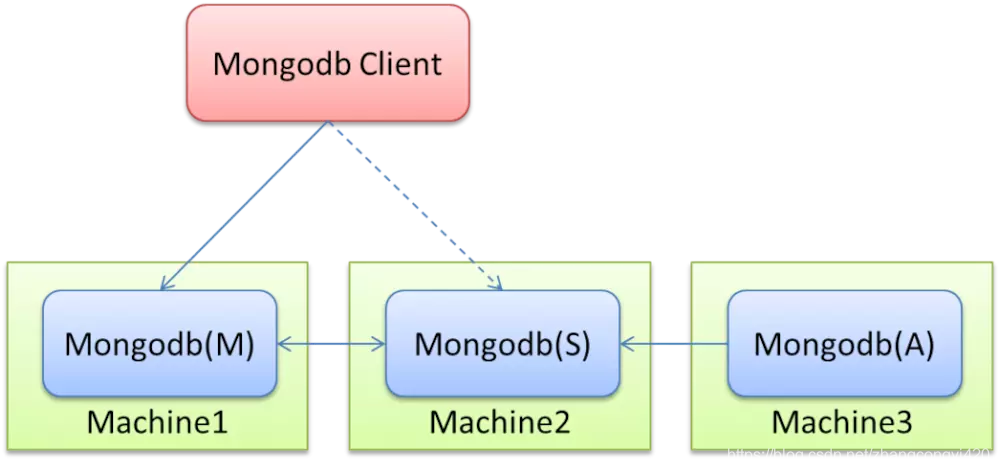
Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
相信大家看到这里是不是可以联想到redis的一种集群模式,即哨兵模式跟这个原理很像,确实如此,仲裁节点就像是一个哨兵,当监听到其它的某个节点挂了,会重新选择某个节点提升为主节点继续对外提供读写服务,从而保障集群的高可用性,减少人工干预;
下面我们在三台虚拟机上模式搭建一下mongodb的这种副本集模式的集群;
1、环境准备,我这里提前准备好了三台虚拟机,
192.168.111.134
192.168.9.147
192.168.111.133
2、上传mongodb的安装包
我这里放在 /usr/local 目录下, tar -zxvf mongodb-linux-x86_64-4.0.9.tgz
3、为使用方便,将解压后的文件命名为mongodb
mv mongodb-linux-x86_64-4.0.9 mongodb
4、创建相关目录
mkdir data
mkdir logs
mkdir conf
cd logs
touch master.log
cd conf
touch mongodb.conf
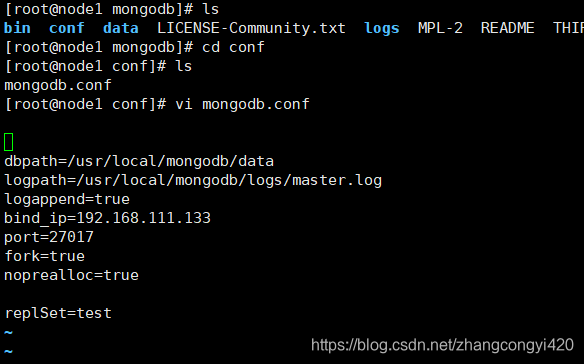
5、创建配置文件
进入conf目录,创建mongodb.conf,并编辑,
6、以上是在主节点做的操作,在另外的两个节点上做同样的配置即可,只需要修改端口号和相应的目录文件地址,下面帖上配置文件,
1 | #master配置 |
其实里面的配置还有很多,大家可以参考相关资料完善其中的配置,这里是基本的配置保证集群能够正常启动
7、做完了上述的配置基本上就可以了,下面我们就来启动集群,
进入三个节点的bin目录下,执行,看到如下信息就表示启动成功了,三个节点做同样的启动操作,
/usr/local/mongodb/bin/mongod -f /usr/local/mongodb/conf/mongodb.conf

8.配置主、备、仲裁节点
#连接到节点
./mongo 192.168.111.133:27017
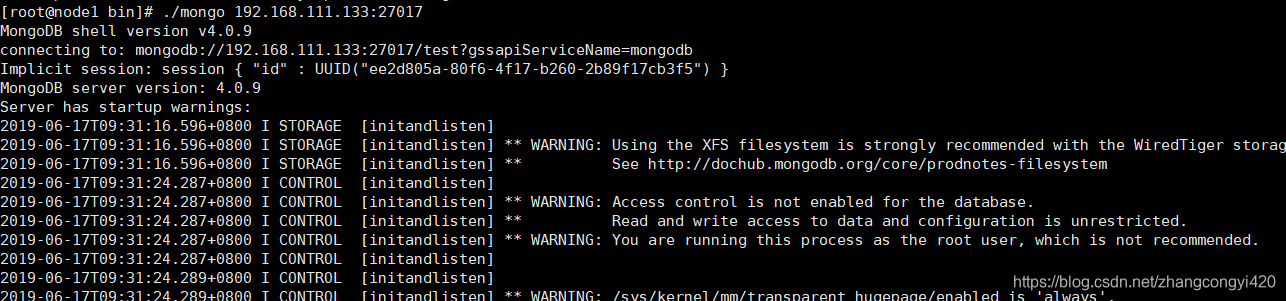
忽略启动的警告信息,没有报错就是连接上了客户端,
初始化并建立三个节点之间的信息,使用如下命令,大家修改为自己机器的IP
cfg={ _id:“test”, members:[ {_id:0,host:‘192.168.111.133:27017’,priority:2}, {_id:1,host:‘192.168.9.147:27017’,priority:1}, {_id:2,host:‘192.168.111.134:27018’,arbiterOnly:true}] };
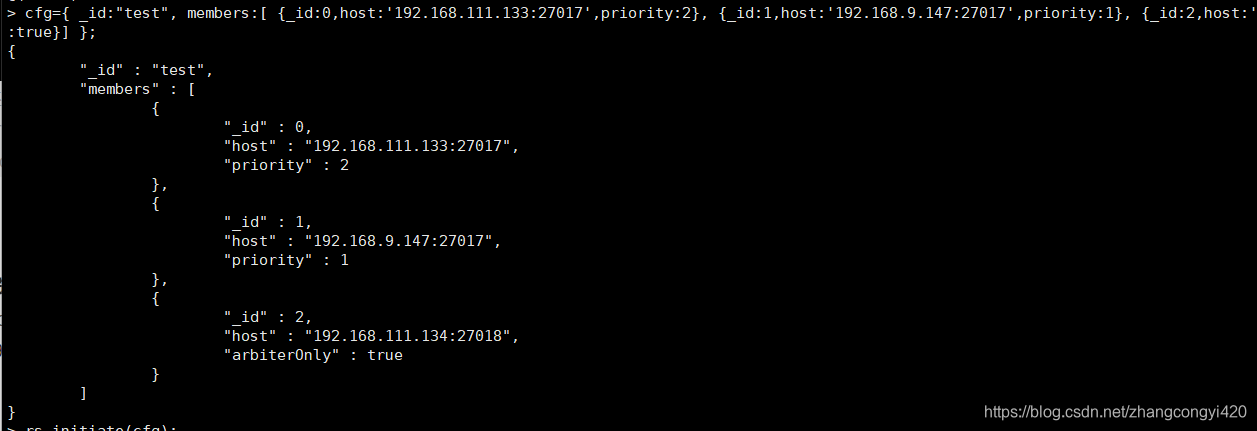
可以看到,各个节点的基本信息已经展示出来了,接着执行,
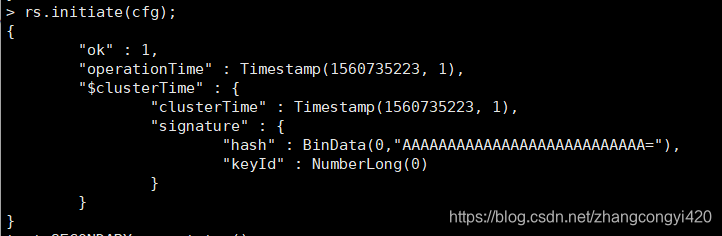
rs.initiate(cfg);
最后,执行rs.status();查看集群的状态,
1 | { |
各个节点的状态比如节点的健康状况,是否主节点等都可以清楚的看出来
到这里,mongodb的分片集群模式就搭建完毕,最后谢谢观看!